LLVM 循环优化
LLVM 是一个广为使用的编译器套件,也是苹果官方的编译器。LLVM 前端可以把高级代码转换成 LLVM 自身的中间代码(IR),而后端再把 IR 翻译为目标平台的机器码。而 LLVM 提供的优化器 opt 可以优化 IR 代码,并生成优化过的 IR 代码。在之前的博客中,我已经探索过使用 clang 来优化一个简单的程序。在那个简单的循环程序中,较为影响性能的就是 Loop Unrolling 优化。我也做出了一些性能测试。
但是,单纯的用 clang -O3 来分析 Loop Unrolling 的性能影响是不科学的。在一个较为复杂的程序中,会有很多处可以优化的地方。而如果想要对比某一种优化策略带来的效果,则最好只做这一种优化(控制变量)。比如,用下面的命令来做 Loop Unrolling 优化,则带来的副作用就少得多:
1 | opt -mem2reg -simplifycfg -loops -lcssa -loop-simplify -loop-rotate -loop- |
编译 LLVM
指定 LLVM opt 要运行的 pass 来控制优化种类没有想象中的那么直观,经常会得不到想要的结果。如果在输入命令的时候带上 -debug 或者 -debug-only=<pass name> 标签,就可以获得一些 debug 的信息,会非常有帮助。然而,直接下载安装的 LLVM 是默认关闭这个选项的。这就需要我们自己编译 LLVM,并在编译时指定打开 assertion -DLLVM_ENABLE_ASSERTIONS=On。
下载最新版本的 LLVM:
git clone https://github.com/llvm/llvm-project.git
clone 后,cd 进入 llvm-project 文件夹。
LLVM 不支持直接在工程文件夹下编译,需要我们自己新建一个构建文件夹:
mkdir build
cd build
然后开始生成编译所需的文件:
cmake -G <generator> [options] ../llvm
多数开发者都会选择用 Ninja 来编译。所以,要先安装 Ninja。如果在 macOS 下,可以用 brew 来安装:
brew install ninja
一个例子:
1 | cmake -G 'Ninja' -DLLVM_ENABLE_PROJECTS='clang;<other build targets>' -DCMAKE_INSTALL_PREFIX=<your install path> -DLLVM_ENABLE_ASSERTIONS=On |
稍等一段时间后,就会生成所需要的文件。然后就可以用 Ninja 来编译了:
ninja
编译花费的时间比较久,可能需要几个小时。编译完成之后,就可以用 Ninja 来安装了,安装地址就是之前指定的地址。
ninja install
Ref: http://llvm.org/docs/GettingStarted.html#getting-started-quickly-a-summary
Loop Interchange
下面的代码可用来测试 Loop Interchange:
1 |
|
由于二维数组在内存中仍是线性排列,因此先在行内循环效率更优。这是因为行内元素的距离更近,符合空间局部性原理,缓存命中率会更高。在上面的程序中,先做了列内循环,所以可能会被 Loop Interchange 优化循环顺序。
生成 IR 代码,为下一步优化做准备:
1 | clang -O3 -mllvm -disable-llvm-optzns interchange.c -emit-llvm -S -o interchange.ll |
这里用 O3 是因为,如果是 O0 的话,LLVM 就会阻止后面的优化器进行优化(可参见 LLVM 源码)。所以后面又先暂时禁止了 opt 直接自动优化。
之后开始使用 opt 进行优化。虽然 LLVM 的 pass 依赖会自动管理,但有些必要的准备工作还是不可避免的:
1 | opt -mem2reg interchange.ll -S -o interchange.ll |
这样就生成了 interchange.ll 和 opt.ll 两个 IR 代码文件。用 llc 来将他们转换成汇编代码:
1 | llc interchange.ll -o un.s |
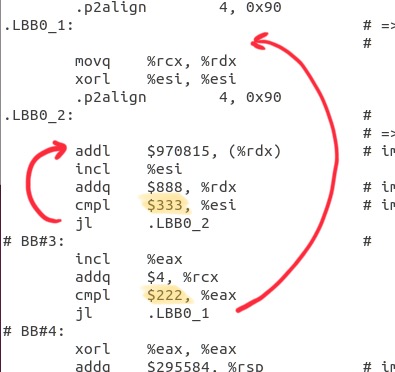
在未优化的汇编代码中,可以看到循环和 C 语言中的一样,内层为 333 次,而外层为 222 次。

而在 Loop Interchange 之后,我们可以发现两个循环的顺序被颠倒了。
将汇编代码编译为可执行文件。为了让 gem5 模拟器运行,需要静态链接:
1 | clang opt.s -o interchange --static |
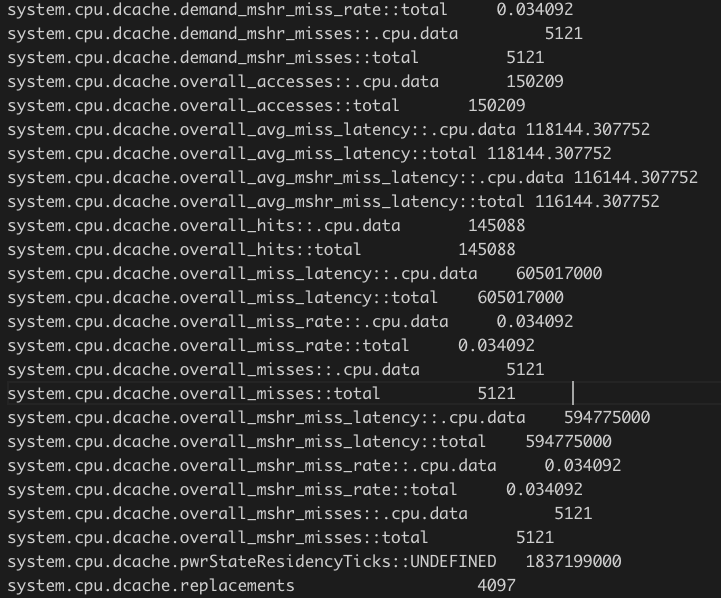
经过 gem5 模拟,优化前执行了 1837199000 个 tick,优化后是 1767821000 个 tick。可以发现优化后程序运行的时间变短了。之前提到过,interchange 可以提高 cache 的命中率。优化前的数据:
优化后:
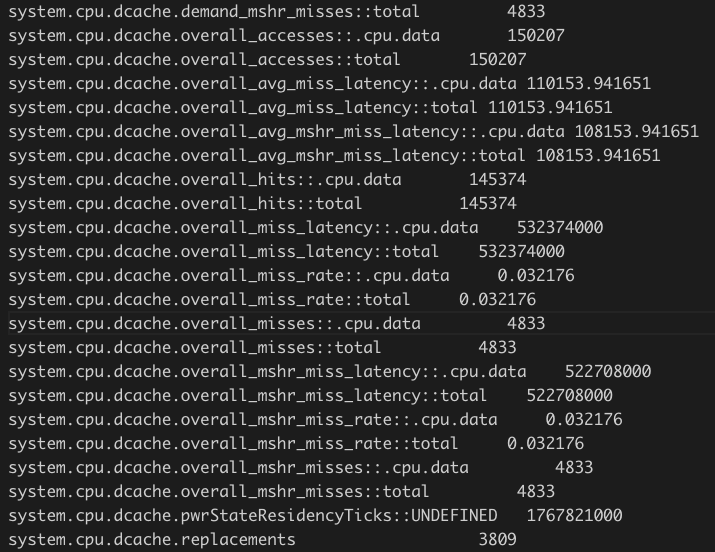
我们可以看到 data cache 的 miss rate 确实下降了一点,好像不是很明显,但是,miss 次数确实是大幅下降了的。
Loop Unswitch
下面的代码可以用来测试 Loop Unswitch:
1 | int main() { |
Loop Unswitch 可以将循环内的条件判断语句移到循环外部,从而在不影响运行结果的前提下节约不必要的判断语句。
1 | clang -O3 -mllvm -disable-llvm-optzns unswitch.c -emit-llvm -S -o unswitch.ll |
未优化时的 IR 代码如下:

可以看到判断语句和 C 语言中的一致,在循环内部。而优化后:

原来的循环被拆成了两个独立的循环(判断语句在循环外)。我有时展示 IR 代码,有时展示汇编代码的原因是,有时 IR 代码更加易读,有时汇编代码更易读。但由于汇编代码时从 IR 代码翻译来的,所以本质上是一致的。
经 gem5 模拟,未优化时用了 101847000 个 tick,而优化后使用了 93526000 个 tick。程序耗时减少了。
Loop Reduce
下面的代码可以用来测试 Loop Reduce:
1 | int main() { |
在 CPU 指令中,有的指令更加耗时。比较耗时的指令一般有 load, store, 以及乘除法等等。Loop Reduce 可以把一些较为耗时的代码转化为更快的指令。比如,这里的乘法就可以优化为累加。
1 | clang -O3 -mllvm -disable-llvm-optzns reduce.c -emit-llvm -S -o reduce.ll |
未优化时:

可以看大 IR 代码中使用了 mul 指令。这是比较耗时的。
而优化后:

可以看到 LLVM 把乘法转换成了加法。而加法操作就要快多了。
经过 gem5 模拟,未优化时消耗了 115056000 个 tick,而优化后只用了 98250000 个 tick。还是加快了许多的。
总结
LLVM 还有很多循环优化选项,亦有 polly 循环优化器可以执行更多的优化操作。然而,直接选择优化级别进行优化较为简单,而想要具体指定优化 pass 就较为困难了。一开始我以为是有相关的依赖,但是经过发送邮件询问 LLVM 社区,有人回答 pass 依赖是自动被管理的。想要知道具体的步骤还是较为困难的,我目前也没有找到什么特别好的方法。所以虽然对一些其他的优化很感兴趣,但也没有机会尝试了。有点遗憾。