Understanding MobileNet v2
随着深度学习的发展,神经网络为了追求精度,结构越来越深、参数也越来越多。Google 推出的 MobileNet 在 accuracy 和 latency 之间做了平衡,更适合在计算力不足的移动端和嵌入式设备上应用。由于参数量比 ResNet 等网络少了很多,也适合我们在研究初期快速验证想法。
如果只是简单使用 MobileNet,那么 Pytorch 已经内置了现成的实现。但是如果想要在网络的基础上加以改动,则需要我们对 MobileNet 的结构有所了解。
MobileNet v1
首先来看一下初代 MobileNet 是如何减轻计算量的。
Standard Convolution
传统的卷积操作如下:
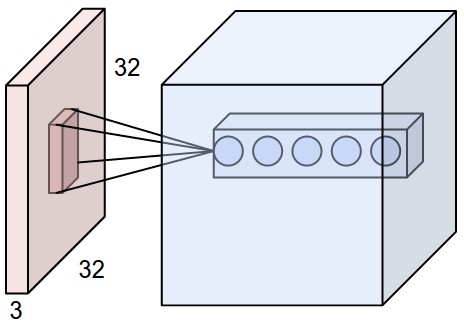
假设上一级的输入尺寸为 32x32x3,我们可以用 5 组不同的卷积核去做卷积。每组卷积出来的结果为输出的其中一层。在 stride=1 且有 padding 的情况下,可以得到 32x32x5 的输出。卷积后的尺寸大小计算公式为:
$$
OutputSize = (InputSize - KernelSize + 2\cdot Padding)/Stride + 1
$$
具体过程可以参考 CS231N 的介绍 。
这样的标准卷积所需要的计算量为:
$$
{D_k}^2\cdot C_i \cdot C_o \cdot {D_i}^2
$$
其中,Dk 为 kernel 的尺寸,Ci 为输入的通道数,Co 为输出的通道数,Di 为输入的 Feature Map 尺寸。
Depthwise Separable Convolution
MobileNet 提出了一种新的卷积方法 Depthwise Separable Convolution (深度可分离卷积)来减少计算量。它分为两个步骤:
- Depthwise convolution:不再同时对输入的每个通道一起做卷积,而是分别做 depth 为 1 的卷积。假如输入的通道数为 5,则分别做 5 次卷积。这样下来,卷积后的通道数和输入的通道数一致。
- Pointwise convolution:传统的卷积,只不过 kernel size 是 1x1 的。这个步骤可以改变输出的通道数。
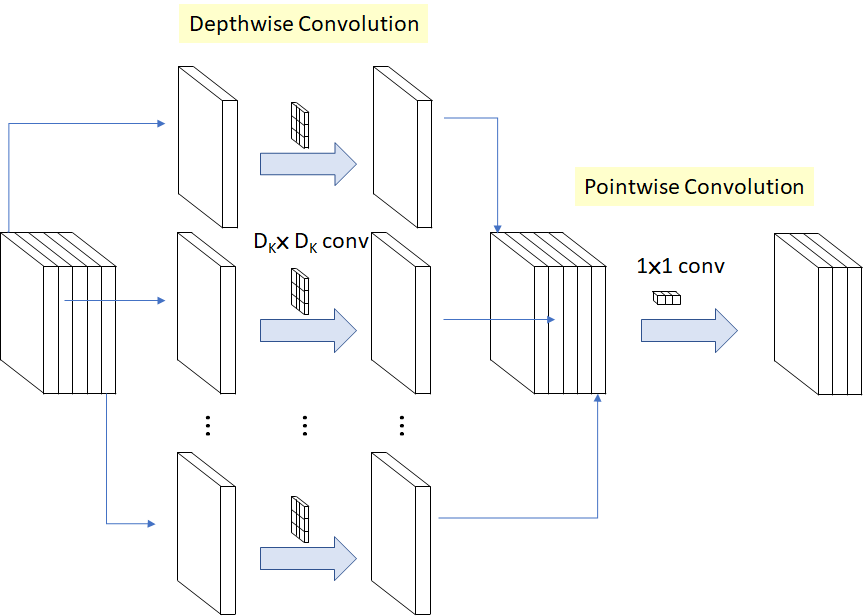
这样的计算成本是:
$$
{D_k}^2 \cdot C_i \cdot {D_i}^2 + C_i \cdot C_o \cdot {D_i}^2
$$
这样,计算量减少为:
$$
\frac{(D_k)^2 \cdot C_i \cdot {D_i}^2 + C_i \cdot C_o \cdot {D_i}^2}
{(D_k)^2\cdot C_i \cdot C_o \cdot {D_i}^2}
=
\frac{1}{C_o} + \frac{1}{(D_k)^2}
$$
假如 Kernel Size 为 3,那么计算量减少为接近原来的九分之一(输出的通道数一般较大,可忽略该项带来的影响),这带来的计算性能的提升是非常可观的。而精度只下降了一点。
需要注意的是,depthwise conv 和 pointwise conv 后面都要接 Batch Normalization 和 ReLU。
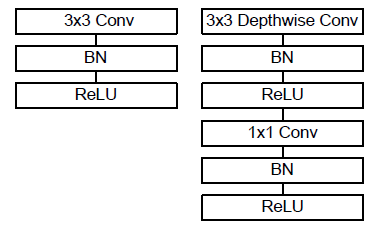
上图中,左边为标准的 3x3 卷积,右边为深度可分离卷积。这里的 ReLU 其实是 ReLU6,即:
1 | y = min(max(0, x), 6) # 让输出最大不超过6 |
作者称在低精度的计算中 ReLU6 有更强的鲁棒性。
整体结构和不足
MobileNet v1 整体结构如下:
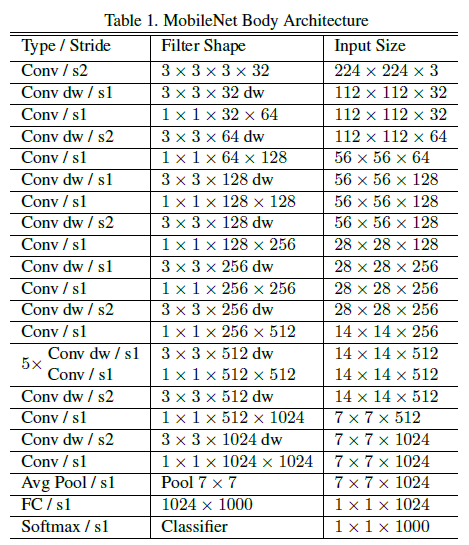
在 ImageNet 上,同样的网络结构下,仅将标准卷积换成 depthwise separable conv,精度损失了 1 个百分点(71.7% 至 70.6%),而参数量从 29.3 Million 显著下降到 4.2 Million。
然而 MobileNet v1 也有不足之处:
首先,其“直筒”形的网络结构影响了精度。后续的 ResNet 等引入了 residual block,通过复用特征带来了分类性能的提升。
其次是 depthwise 卷积的问题。这一点许多资料分析的都不是很清楚,我的个人理解如下(此处存疑):
在输入 channel 数量较少的情况下(depthwise 卷积操作的 feature map 相对来说维度较少),卷积输出的结果更容易出现 0 或负数。在 channel 数量多的情况下,每层之间的加法更可能把最终的值累加为正数。0 或负数的值通过 ReLU 后梯度为 0,导致反向传播时再也无法进行更新,造成“神经元死亡”。除了可以增加 channel 数量之外,ResNet 等网络的特征复用也有助于缓解这一点。
MobileNet v2
MobileNet v2 中,重点解决了 v1 中存在的问题。
改动部分
MobileNet v2 中最重要的结构 bottleneck residual block 如下图所示:
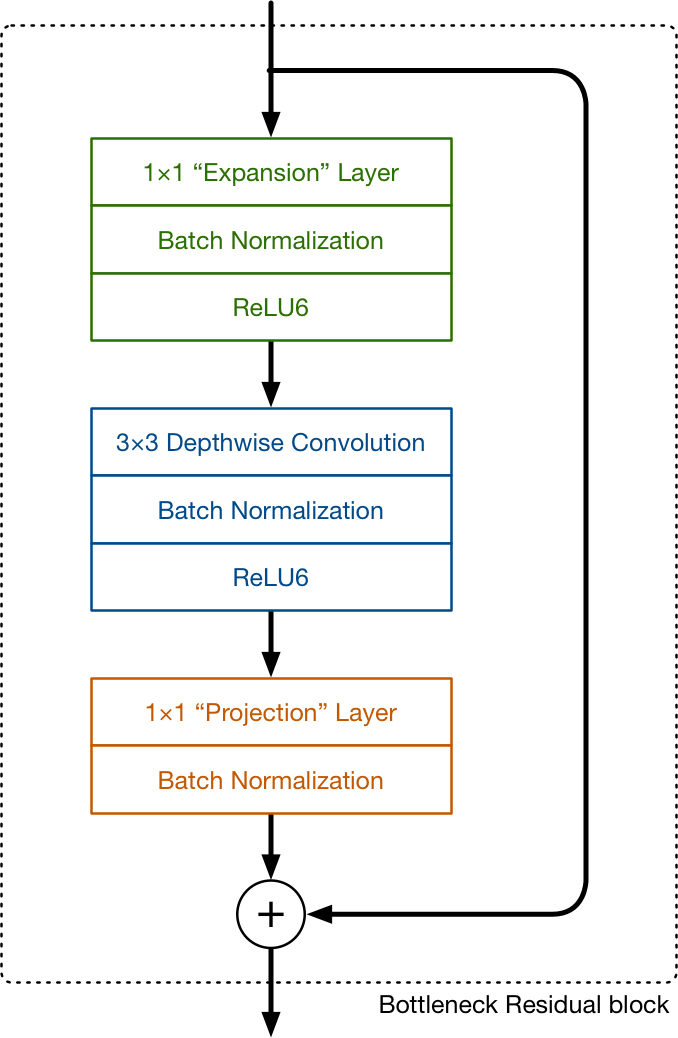
后面两部分仍然是熟悉的 depthwise 和 pixelwise 卷积。但是在 v2 中,1x1 的 pixelwise 卷积发挥了不同的作用。在 v1 中,通过 1x1 卷积后 channel 数不是和原来一致,就是扩大为原来的两倍。而在 v2 中,projection 的 1x1 卷积却用来减少 channel 的数量。这也是为什么它被称为 Projection Layer。由于流过网络的数据在这里变少了,所以作者叫它 bottleneck。
回过头来看第一个部分:Expansion Layer。这一层用来增加 channel 个数,即升维。它也是采用了 1x1 的卷积。具体增加几倍是网络的一个超参数,默认为 6 。它做了和 Projection Layer 相反的操作。Expansion 和 Projection 配合,让这个 block 的输入和输出都是低维的 tensor,而中间做卷积的部分维度更高。
另外就是 v2 中引入了和 ResNet 一致的 residual connection 来复用特征。当然这步只在输入和输出维度一致的情况下才存在。
最后一个改动是,在 projection 1x1 的卷积后面没有跟 ReLU 来当作 non - linearity,而是直接去掉了这层 ReLU,这是因为作者提出在低维度下 ReLU 对特征有破坏作用。

细节解释
为什么要去掉 projection 后面的 ReLU?
ReLU 在高维空间上的能有效的增加 non - linearity,而在低维空间上会造成特征损失。这里 MobileNetV2 的文章也给了一个说明。

在上图中,输入时一个二维的螺旋线。首先通过一个随机矩阵 T 将二维的数据变换到更高的维度;然后通过一次高维的 ReLU。最后,通过逆矩阵 T^(-1) 将数据变换回二维。可见在低维度的情况下,特征损失较为严重;而在更高的维度下,ReLU 过后的特征保存的较为完好。
在 projection layer 后面,由于维度从高维降低到了低维,这个时候 ReLU 就会有破坏的作用。因此 v2 中去掉了这部分的 ReLU。
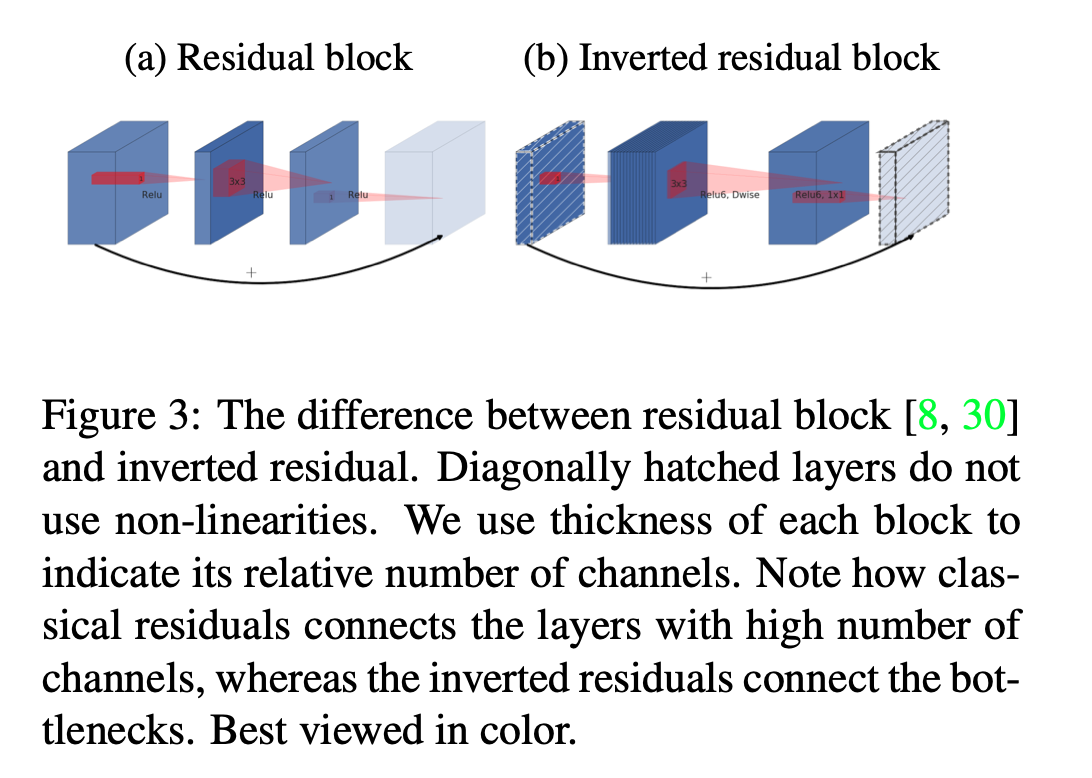
Inverted Residual 是什么意思?
ResNet50 中同样有 1x1 的卷积 bottleneck residual block。但是它是先降维再升维的。在 MobileNet 中,是先升维再降维的。因此命名为 Inverted。
这带来的第一个好处是,提升了维度使得卷积操作后跟随的 ReLU 不易出现“神经元死亡”的情况(参考上面);第二个好处是作者验证得到这样做能占用更少的内存(shortcut between bottlenecks v.s. shortcut between expansions)。
为什么要 Expansion ?
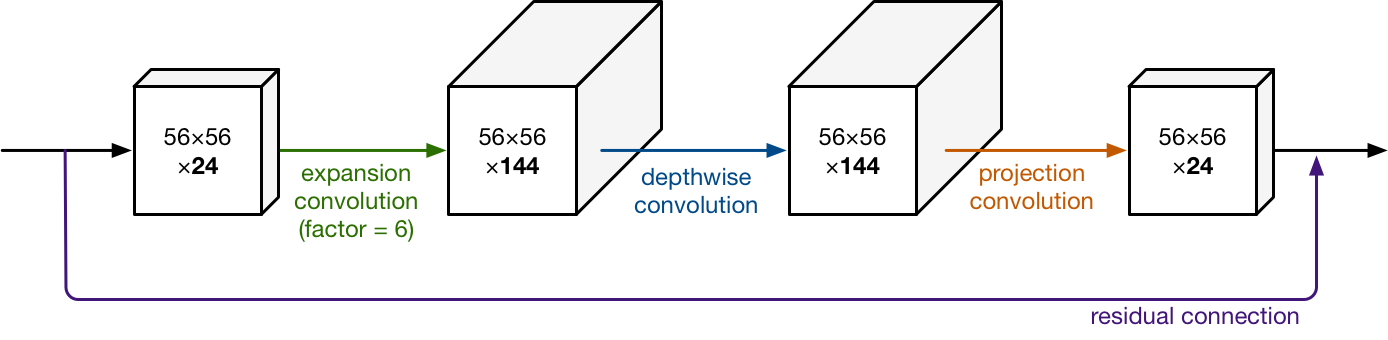
一般随着网络层数加深,通道数会逐渐变多,而 feature map 的尺寸逐渐变小。MobileNet v1 和 v2 也不例外。通过引入了 bottleneck,我们发现 v2 种的 tensor 尺寸比 v1 中的更小(7x7x320 vs 7x7x1024)。更小的 tensor 会更加节约计算资源。但是如果 channel 数过少,卷积操作不能很好的提取出足够的信息。因此 Expansion Layer 被用来增加 channel 数。由于是通过 1x1 的卷积实现的,因此是网络通过训练,学习到的如何 uncompress data。
References
[1] MobileNetV2 原文 https://arxiv.org/pdf/1801.04381.pdf
[2] https://machinethink.net/blog/mobilenet-v2/
[5] https://perper.site/2019/03/04/MobileNet-V2-详解/
[6] https://zhuanlan.zhihu.com/p/67872001
[7] https://www.jianshu.com/p/2eec2b8b885b
[8] 知乎讨论 https://www.zhihu.com/question/265709710
[9] ResNet 结构梳理 https://zhuanlan.zhihu.com/p/54289848