Brief Intro to ViT
最近 Transformer 非常流行。Transformer 本身应用在 NLP 中,直到 2020 年 Google 带来了视觉领域的应用 Vision Transformer(ViT)。其在图像分类上达到了接近 SOTA 的程度,标志着视觉中 self-attention 类网络也可以很好的代替 CNN 完成工作。许多人甚至认为 Transformer 开启了视觉的新时代,未来能完全取代 CNN。
在介绍 ViT 之前,我们不得不先了解一下 NLP 中的 Transformer。
Attention
我们为什么需要注意力机制?简单来说,注意力机制就是给原始数据乘上一个权重,从而使得变换后的数据更利于学习。这个权重就是所谓的注意力系数。我们通过给 RNN 网络引入一个新的注意力模块,即一个新的神经网络,来负责学习怎样分配权重。
应用在自然语言时,比如 “Bank of the river” 这句话。如果只看 Bank,可能会联想到银行。但是如果引入注意力机制,Bank 和 river 就会产生很强的关联性。这样经过新的权重的处理后,Bank 对应的向量可能就会更偏向于“河岸”,而不是“银行”。这样就从直观上解释了为什么经过 self- attention 之后网络的效果会得到提升。
具体是怎样做这个权重的变换呢?下图展示了对向量 V3 做变换的过程:
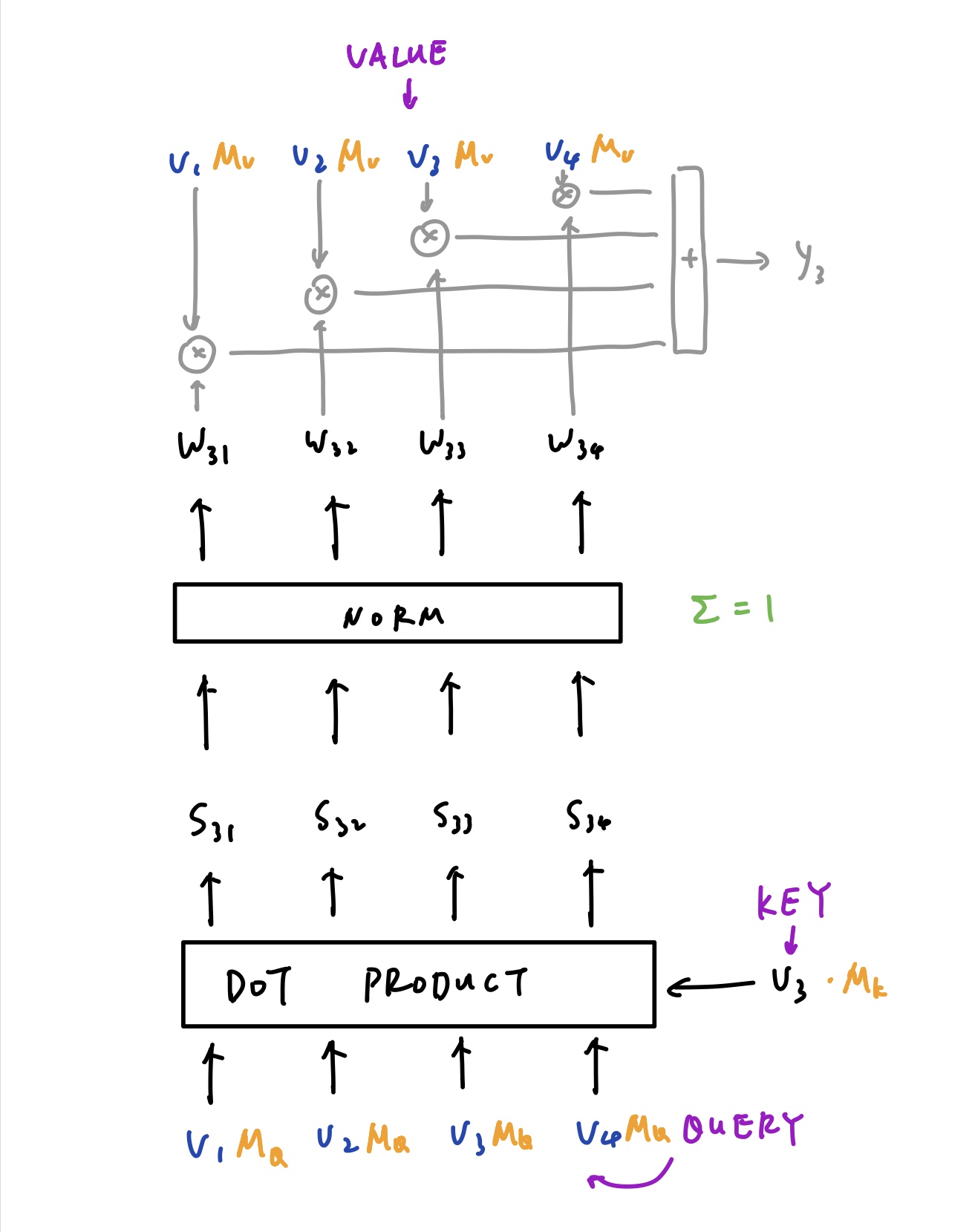
V3 分别和所有的向量 V1 - V4 相乘,得到一组 score S。这些 score 经过归一化之后即得到了权重 W。W 再分别和 V1 - V4 相乘再相加,即得到了 V3 所对应的 Y3。类似的,我们也可以得到 Y1,Y2 和 Y4。V3 被称为 Key,上下两组 V1 - V4 被称为 Query 和 Value。
但是这样的过程是没有“学习”的。因此引入一些矩阵 M-k,M-q 以及 M-v 与 K、Q、V 相乘,即三个 Linear 层。这样这些参数就可以随着训练更新了。
上图稍加转换,就得到了论文中提出的 Scaled Dot-Product Attention,仅多引入了一个 Scale 项和 Mask 项而已。Mask 是为了在训练过程中,网络不会提前看到未知的数据。
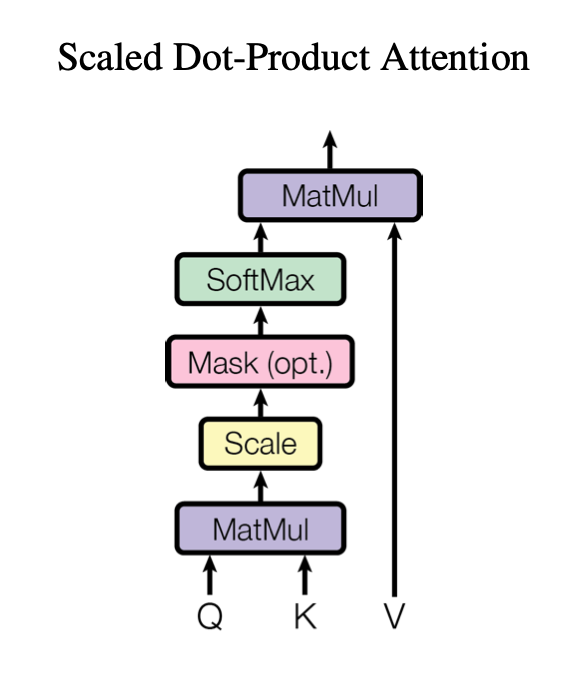
当 Q、K、V 相同时,即为 Self- Attention。
Multihead - Attention
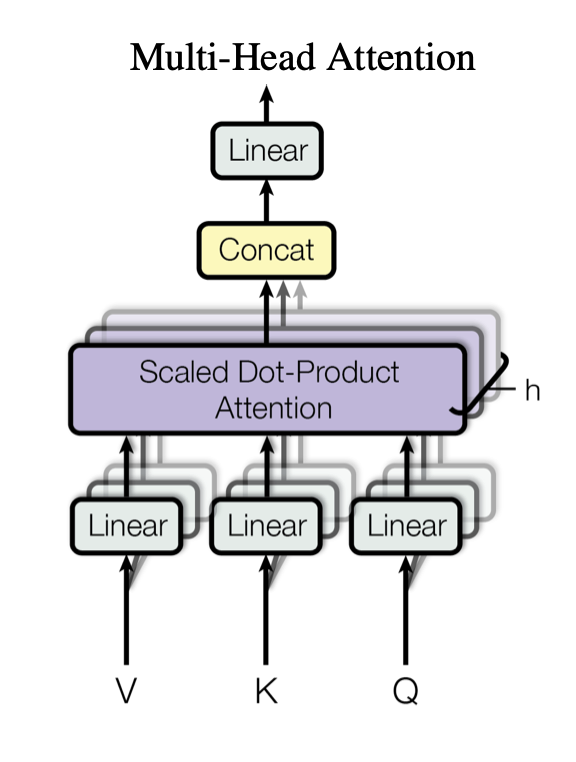
Multihead - Attention 将 Q、K、V 分割成多块,然后并行处理,最后再连接到一起。这样不仅可以增加运算效率,还可以让不同位置的数据(比如一个句子中不同位置的单词)学习到不同的注意力模式。由于我们需要对句子中的每个词向量都分别计算注意力,而这个计算过程本身并不相关,因此完全可以并行处理。
RNN 的弊端
RNN 有两个主要问题:
- 由于 RNN 需要接收上一个时刻的状态作为输入,因此不能很好的并行处理。训练速度较慢。
- 随着链条越来越长,梯度会逐渐变小,误差没有办法很好的传播到较久之前的时刻。
随着 LSTM / GRU 的提出,第二个问题一定程度上得到了解决。但是由于网络更加的复杂了,训练会变得更慢。
Transformer 的提出摒弃掉了 RNN 的结构,因此可以很好地并行化处理。
Transformer
Transformer 的网络结构如下:
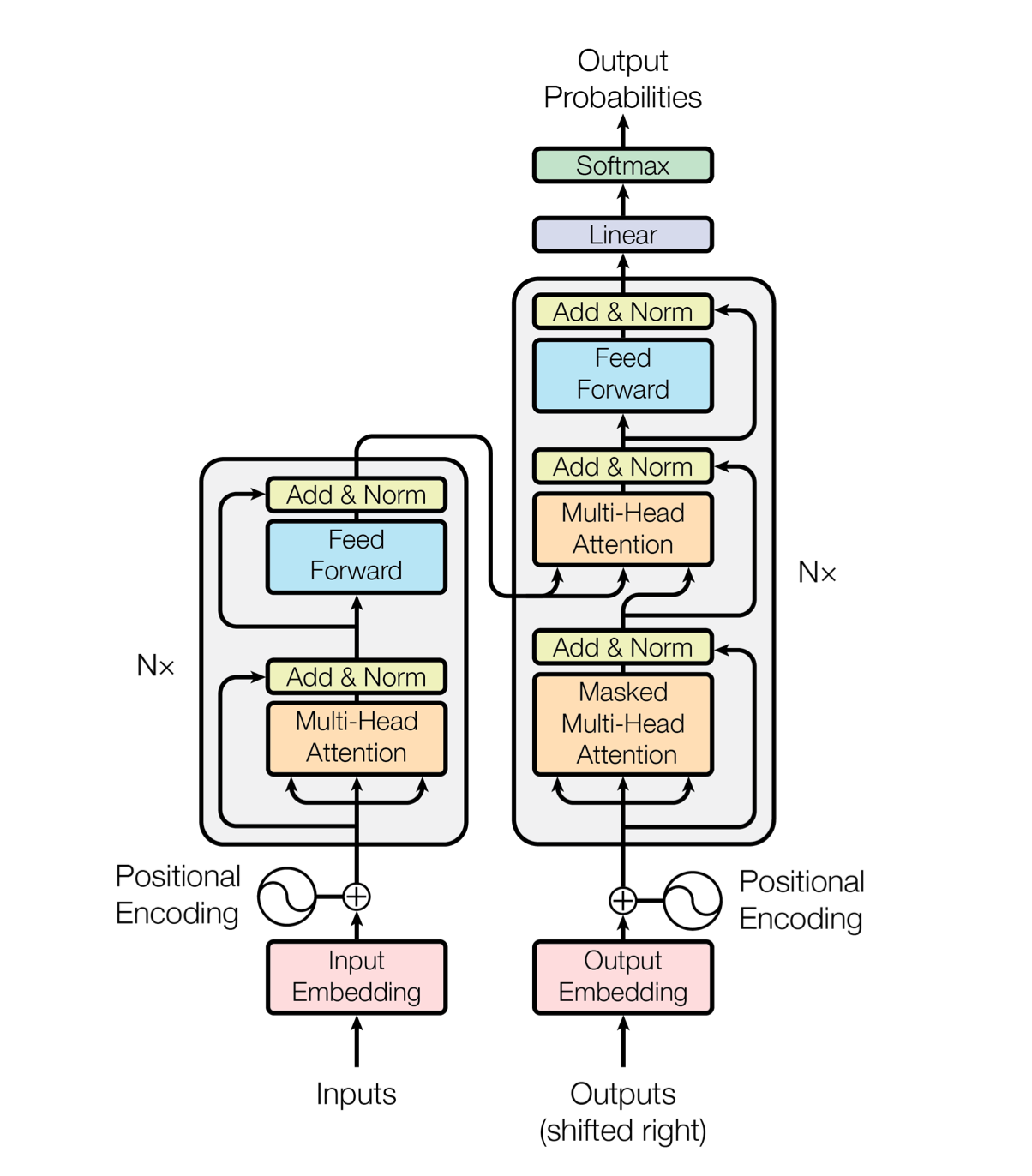
左右两部分分别是 Encoder 和 Decoder,这是为 Seq2Seq 类型的任务设计的,例如机器翻译。在 ViT 中,我们只需要 Encoder。不过两者非常相似,理解了 Encoder 也就理解了 Decoder。
首先,输入的数据要被 embed 成向量的形式,这个 embed 过程也是通过学习得到的。
Embed 得到的向量要加上 Positional Encoding。这带来了位置信息,否则网络就不知道一个词向量处于句子中的哪个位置。
接下来就是上面谈过的 Multi-Head Attention 了。Q 和 K 相乘得到了 score,更高的 score 代表了更强的注意力,小的 score 最终经过 Softmax 后会区域 0,即抹掉不相关的东西。这里要做 scale 是为了防止乘法得数过大带来不稳定。
处理过后得到的输出带有更多的上下文信息,也就有更强的表现力。结果通过残差模块和之前的层相连。
最终,Encoder 学习到的隐含表示将作为 Decoder 的一项输入。
ViT
如上面所说,ViT 只用到了 Encoder 的结构:
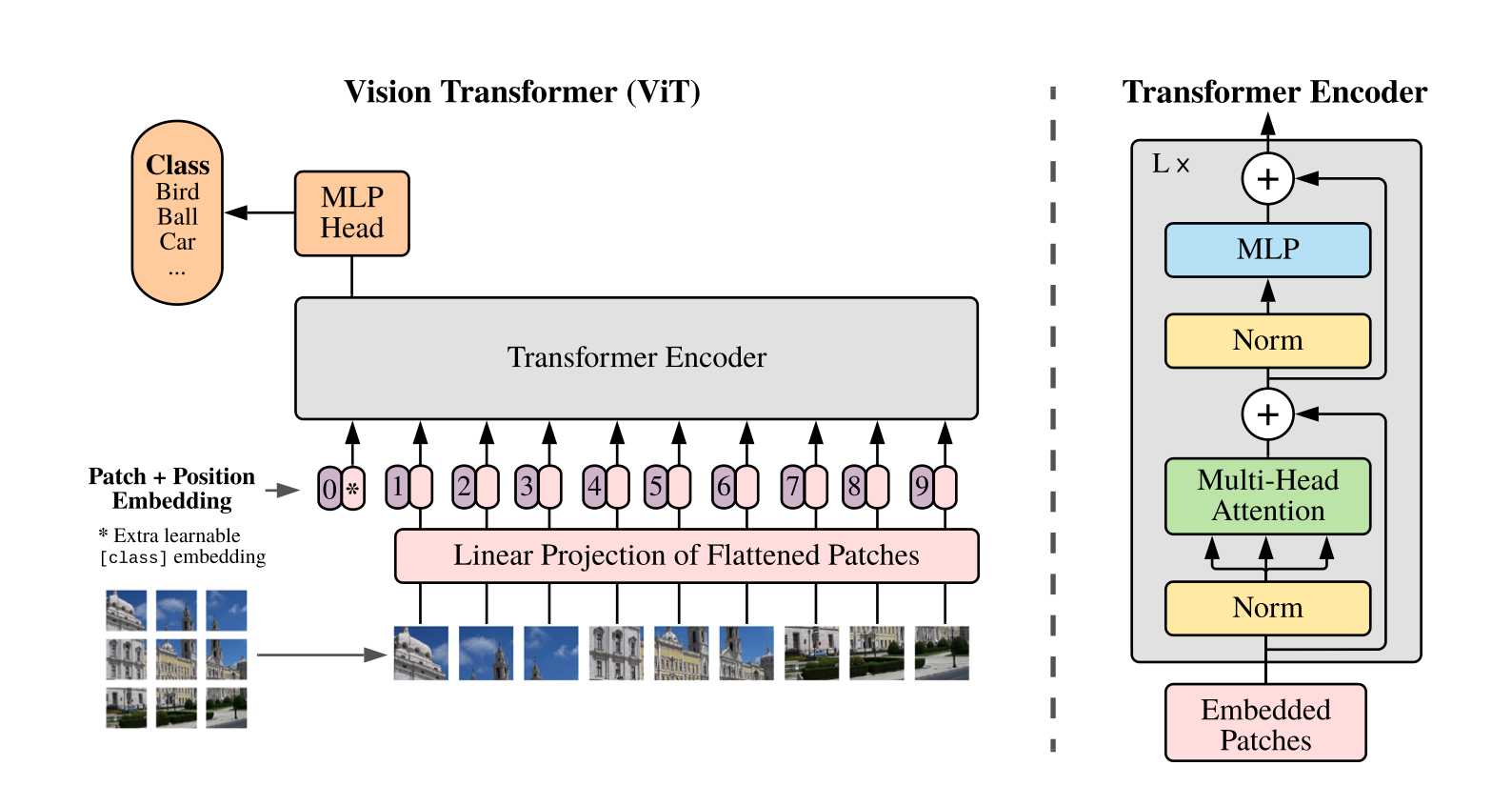
ViT 中,将图片拆分成了多个小块作为输入。论文中给出的是 16x16,也就是标题 An Image is Worth 16x16 Words 的由来。Transformer 的输出接上了一个 MLP 来实现最终的分类。
无需卷积?
1 | class PatchEmbedding(torch.nn.Module): |
在 Patch + Embedding 过程中,ViT 可以直接将图片切割成多个小块,再通过一层 Linear 来做 Embedding。然而实际上,使用 stride = kernel_size 的卷积运算来分块会带来更好的分类效果。因此 ViT 其实也是依赖了卷积的。
疑问(ToDo)
想彻底理解 ViT 需要的背景知识比较多,比如 Transformer、Attention 等等。目前我仍有一些地方存在困惑:
- 为什么需要插入一个 class_token?
- 通过 ViT 对 MNIST 进行分类确实达到了不错的效果。但是当我把 Multihead Attention 的实现更换成 Pytorch 自带的实现后,分类效果就显著下降了。虽然阅读了源码但是还没有查到问题所在。
没有问题的实现:
1 | class MultiheadAttention(torch.nn.Module): |
使用 Pytorch 自带的实现(有问题):
1 | class MultiheadAttention(torch.nn.MultiheadAttention): |
Update *
使用 Pytorch 自带的 MultiheadAttention 的问题已经解决:
睡觉的时候突然想到会不会和计算图有关。因为将相同的 x 传入了三次,在反向传播计算梯度的时候,可能会把 K、Q、V 的梯度都累加到 x 上。于是把代码改成了这样:
1 | class MultiheadAttention(torch.nn.MultiheadAttention): |
将其中两个从计算图中 detach 出来。之后网络性能果然正常了。经过实验,保留 key 或者 value 都可以达到不错的精度;保留 query 不行。
只学会框架的使用只能解决浅层的问题,当稍微复杂一些的问题出现时,就必须对底层工作原理有所了解才可能解决。但是不管怎么说,问题解决了还是值得开心一下的🎉
References
- ViT 原文 https://arxiv.org/pdf/2010.11929.pdf
- Transformer 原文 https://arxiv.org/pdf/1706.03762.pdf
- ViT 的介绍,运算步骤介绍的比较清楚 https://www.kaggle.com/abhinand05/vision-transformer-vit-tutorial-baseline/#data
- Transformer 的视频介绍 https://www.youtube.com/watch?v=TQQlZhbC5ps&t=1s
- 另外一个非常好的视频介绍,从 self-attention 一直到 Transformer https://www.youtube.com/watch?v=yGTUuEx3GkA&list=PL75e0qA87dlG-za8eLI6t0_Pbxafk-cxb&index=10
- Transformer 的 Pytorch 实现。作者非常热心,回复了我的邮件提问(虽然 sadly 并没有解决)https://towardsdatascience.com/implementing-visualttransformer-in-pytorch-184f9f16f632
- 使用 Transformer 训练 MNIST https://towardsdatascience.com/a-demonstration-of-using-vision-transformers-in-pytorch-mnist-handwritten-digit-recognition-407eafbc15b0
- Pytorch 官方 Transformer 教程 https://pytorch.org/tutorials/beginner/transformer_tutorial.html#load-and-batch-data
- https://zhuanlan.zhihu.com/p/266311690