GRU Forward and Backward Pass
GRU 是 LSTM 的一个变体。LSTM 的一些操作显得冗余,例如它既有记忆门,又有遗忘门。GRU 中就把这两个门合并成了一个。另外 LSTM 分别维护着 cell state 和 hidden state,也显得重复了。GRU 在这个基础上做了简化,因此参数会更少、形式也更简洁。
Forward Pass
GRU 的结构如下图所示:
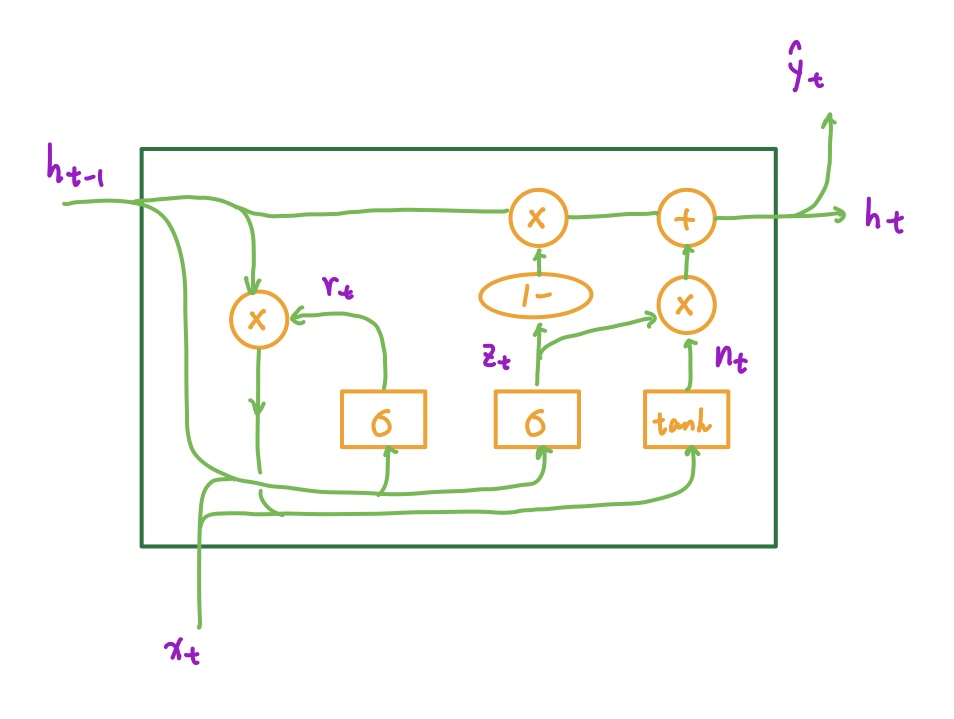
运算公式如下:
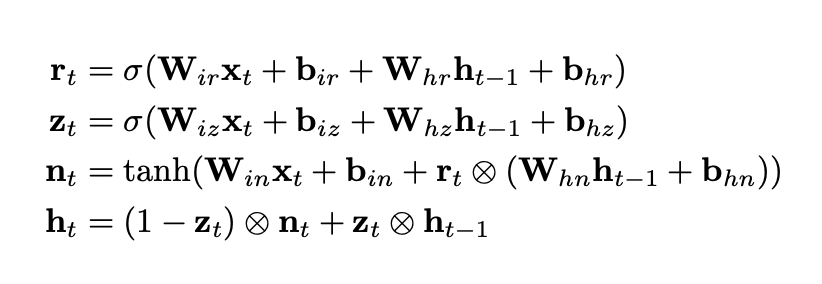
注意,这里最后一行的 ht 的计算公式和 PyTorch 的实现是一致的;而 PyTorch 的实现和 Wikipedia 或是网上常见的公式不一致。更常见的公式中,nt 和 ht-1 的位置是调换的。
但这其实并不是 PyTorch 的 bug,两者交换位置没有本质区别。更详细的讨论可以参考 Github 上的 issues:https://github.com/pytorch/pytorch/issues/20129
代码也比较简洁。由于是课程作业的代码,就不放出完整版本了:
1 | r = self.sigmoid(np.dot(self.Wrx, x) + self.bir + np.dot(self.Wrh, h) + self.bhr) |
其中 Sigmoid 实现如下:
1 | class Sigmoid(): |
Backward Pass
求导会稍微困难一些。好在我们可以根据矩阵的维度得到一些提示。一些核心的公式如下,其他的参数求导很类似,就不详细赘述了:
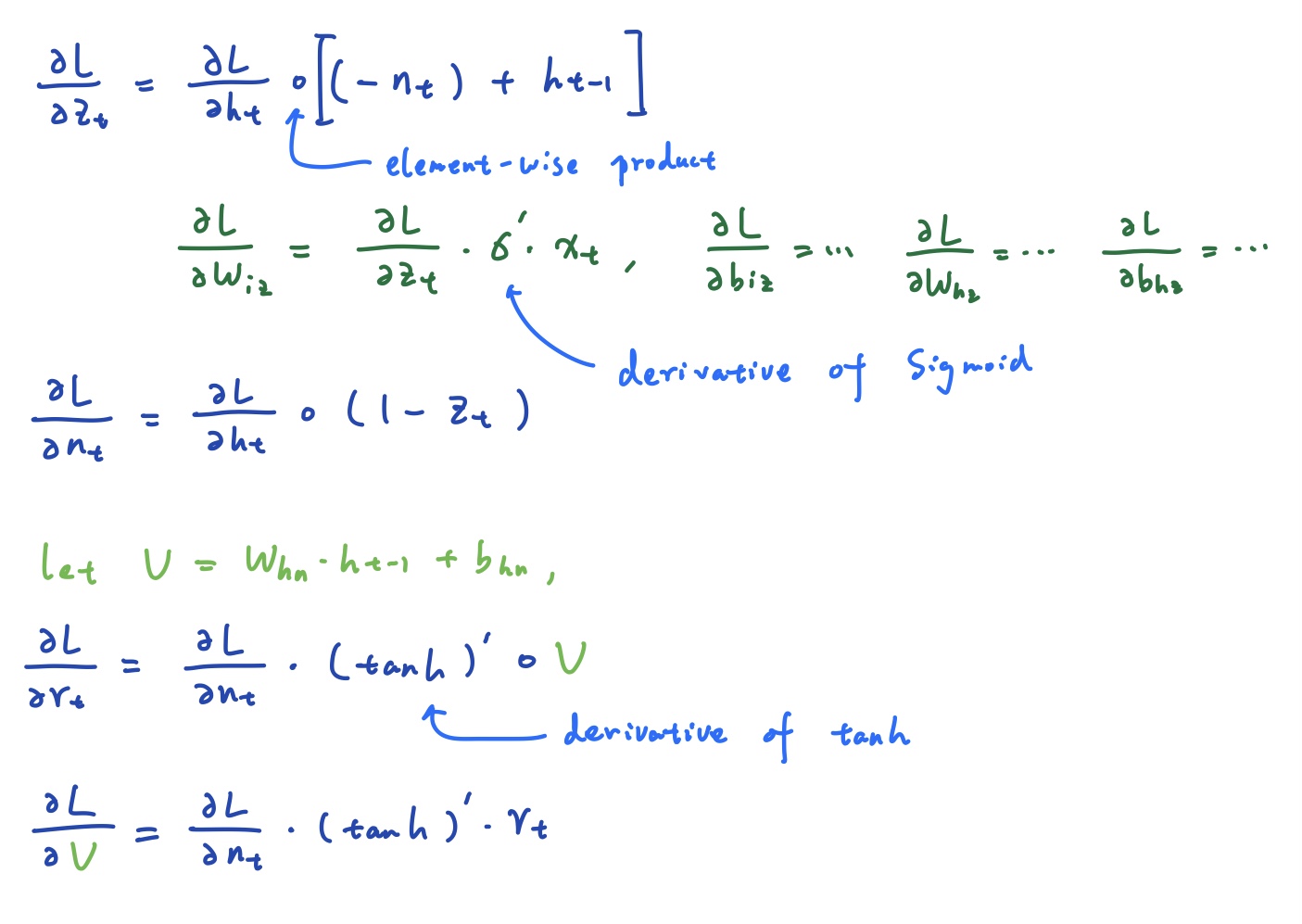
部分代码如下:
1 | d_z = delta * (-1.0 * self.n + self.hidden) |