Channel Attention (CBAM) 注意力机制通过关注相对重要的特征、抑制不必要的特征来对数据进行加权,从而更有利于神经网络总结出数据的规律。通道注意力就是在通道的维度计算出一个权重,也就是给每个通道的重要性打分。比较常用的网络是 SE-Net。
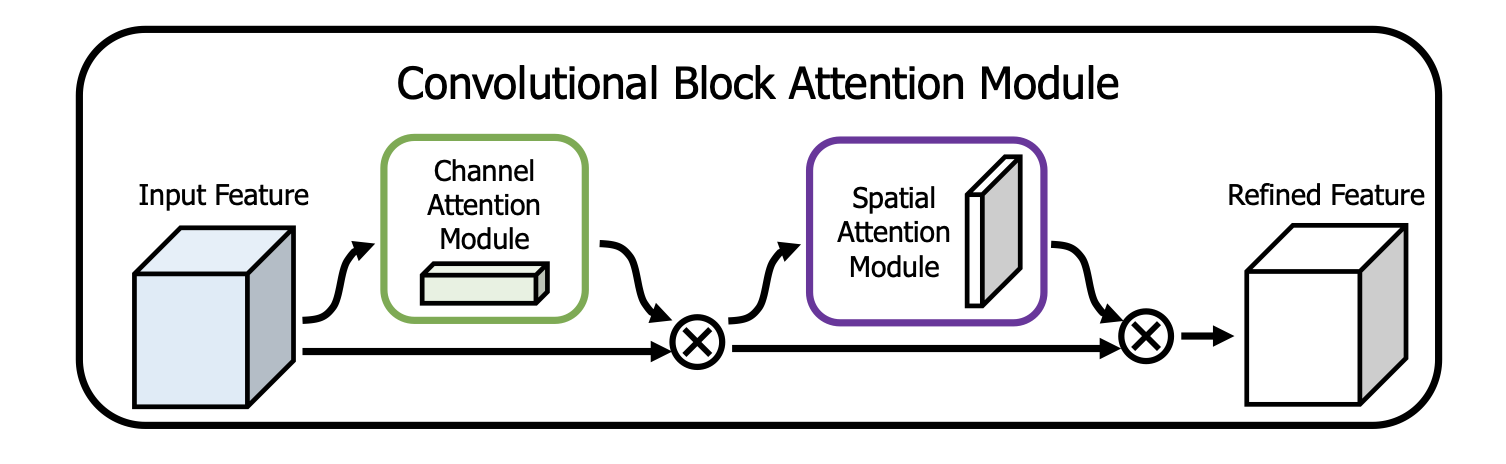
CBAM(Convolutional Block Attention Module)是 ECCV18 的一份工作,以一种简单的方式分别对通道和空间进行注意力计算。CBAM 非常轻量,且易于集成到现有的网络中。由于我们的项目中主要想应用通道注意力,因此可以简单地将后半部分(空间注意力)舍弃。
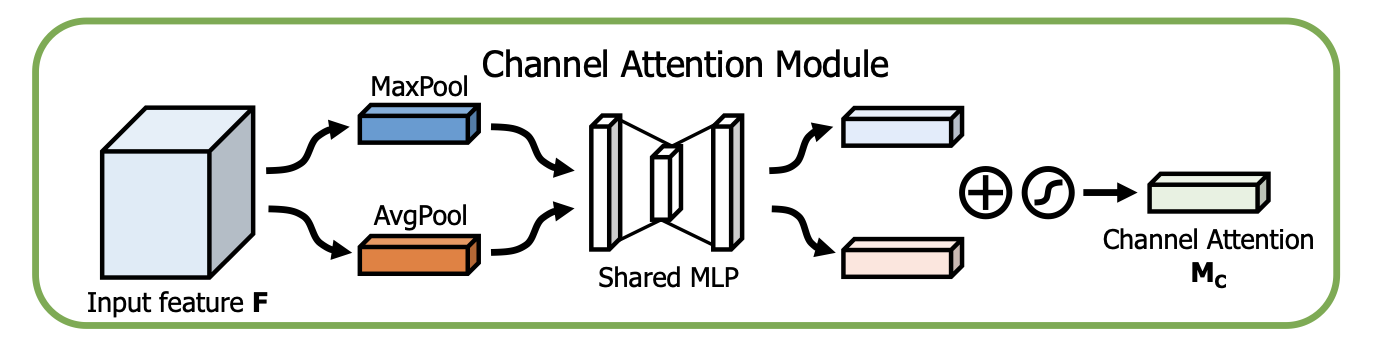
原理 CBAM 论文中提到,SENet 只使用了 average pooling 来做通道注意力的计算,但这并不是最优的做法。CBAM 的通道注意力同时使用了 average pooling 和 max pooling。具体做法如下:
对输入进来的特征图分别做 max pool 和 average pool,沿空间的维度进行压缩,得到两个 1 维的向量(C x 1 x 1)。之后,把这两个向量输入进一个共享的 MLP 中,对结果进行 element-wise 的加和。最后通过一个 sigmoid 激活函数,输出得到通道注意力的分数。
其中使用的 MLP 只有一个隐含层。如果希望减少参数量,可以让隐含层的维度小一些,从而形成一个类似 bottlenet 的结构。
公式如下:
PyTorch 实现 原理比较简单,因此代码实现也并不复杂:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class ChannelAttention (nn.Module): def __init__ (self, input_channels, reduction_ratio ): super ().__init__() self .input_channels = input_channels self .reduction_ratio = reduction_ratio self .hidden_dim = int (self .input_channels / self .reduction_ratio) self .mlp = nn.Sequential( nn.Linear(self .input_channels, self .hidden_dim), nn.ReLU(), nn.Linear(self .hidden_dim, self .input_channels) ) def forward (self, x ): shape = (x.shape[2 ], x.shape[3 ]) avg_pool = F.avg_pool2d(x, shape) max_pool = F.max_pool2d(x, shape) avg_pool = avg_pool.view(avg_pool.shape[0 ], -1 ) max_pool = max_pool.view(max_pool.shape[0 ], -1 ) avg_pool = self .mlp(avg_pool) max_pool = self .mlp(max_pool) pool_sum = avg_pool + max_pool sig = torch.sigmoid(pool_sum) sig = sig.unsqueeze(2 ).unsqueeze(3 ) return sig class CBAM (nn.Module): ''' CBAM only W/ channel attention ''' def __init__ (self, input_channels, reduction_ratio ): super ().__init__() self .input_channels = input_channels self .reduction_ratio = reduction_ratio self .channel_attention = ChannelAttention(input_channels, reduction_ratio) def forward (self, f ): attention_score = self .channel_attention(f) fp = attention_score * f return fp
CBAM 模块可以很容易地插入已有的网络中,比如 MobileNet v2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class MobileNet (torchvision.models.MobileNetV2): def __init__ (self, attention_loc='none' , input_channel=6 , **kwargs ): super ().__init__(**kwargs) self .attention_loc = attention_loc if self .attention_loc == 'last' : self .channel_atten = CBAM(input_channels=self .last_channel, reduction_ratio=1.0 ) elif self .attention_loc == 'first' : self .channel_atten = CBAM(input_channels=input_channel, reduction_ratio=1.0 ) conv = self .features[0 ][0 ] self .features[0 ][0 ] = nn.Conv2d(input_channel, conv.out_channels, conv.kernel_size, conv.stride, conv.padding, groups=1 , bias=False ) nn.init.kaiming_normal_(self .features[0 ][0 ].weight, mode='fan_out' ) def _forward_impl (self, x ): if self .attention_loc == 'first' : x = self .channel_atten(x, return_score=return_score) x = self .features(x) if self .attention_loc == 'last' : x = self .channel_atten(x, return_score=return_score) x = nn.functional.adaptive_avg_pool2d(x, 1 ).reshape(x.shape[0 ], -1 ) x = self .classifier(x) return x
一般来说,CBAM 有两种使用方式:一是在每个残差块中间都使用,二是只用在最后的全连接层之前,只对最终的 feature map 做注意力加权。这里我只实现了应用在输入层(first),或最后一层(last)。
验证 为了验证代码实现的正确性和有效性,我在 CIFAR-10 数据集上做了一个粗略的对比实验。CIFAR-10 是一个十分类的数据集,包含了 60,000 张 32x32 大小的彩色自然图像,类别有飞机、轮船、猫、狗等。该数据集规模较小,比较适合快速验证。
由于每张图片大小仅有 32x32,而 MobileNet 的默认输入是 224x224,如果直接输入,卷积核的尺寸就会显得过大了。出于简便,图像全部被 resize 到 112x112 再输入。这样可以在不太影响运行速度的情况下,尽量不牺牲分类精度。初始 LR 0.01,Batch Size 32,训练 20 个 epoch。
实验结果如下:
Model
Top 1 Acc
MobileNet Baseline
84.53%
MobileNet + Attention (Last)
85.47%
为了验证注意力机制缺失更 focus 在重要的通道上,还做了另一组实验。在正常的 RGB 三通道输入上再叠加三个随机噪声通道,即输入变为 6 通道:
实验结果如下:
Model
Top 1 Acc
RGB Input Baseline
84.53%
RGB + Random Noise
83.73%
RGB + Random Noise + Attention
84.34%
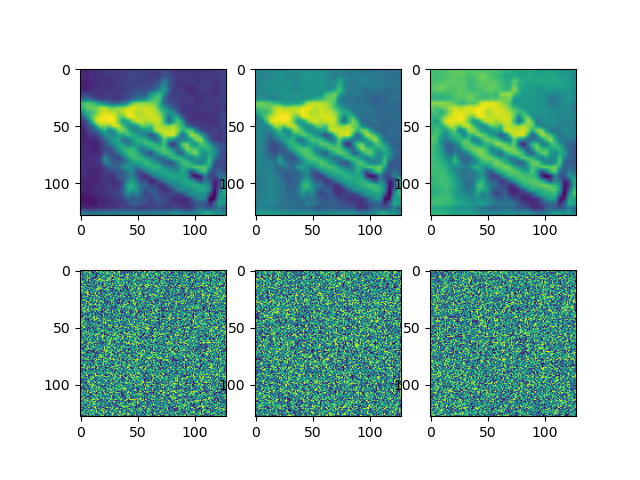
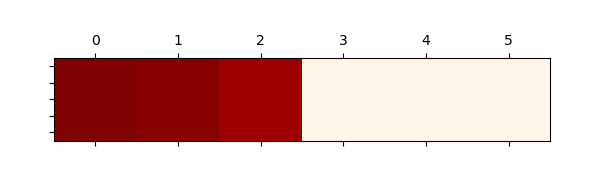
可见增加了三个噪声通道后,确实对网络造成干扰。使用注意力机制可以把精度补救回来。使用分类精度最高的模型,在测试集上随机选取 64 张图片,统计平均通道注意力数值,数值和可视化结果如下:
1 0.9846477 , 0.96408206 , 0.91101015 , 0.00664441 , 0.0050977 , 0.00696521
可见前三个通道的注意力分数确实远高于后三个随机噪声通道,符合直觉。