Loop Unrolling 优化效果对比
循环是计算机程序中非常重要的结构。如果对循环加以优化,就可以大幅提高程序的运行速度。本文通过一段简单的小程序,对比了 Loop Unrolling 前后的性能差异。
什么是 Loop Unrolling
简单来说,循环展开就是把循环中的内容复制多次,然后减少循环次数。这是一种牺牲程序占用空间换取执行时间的优化方法。Loop Unrolling 有利于指令级并行,也有利于 pipeline 调度。
指令级并行(multiple issue)是在同一时刻执行多条指令。这建立在 CPU 的结构”冗余”上。例如,如果我们有两个 ALU,我们就可以同时执行两个 ALU 运算操作。
Loop Unrolling 可以由编译器自动优化。
例子
为了测试 Loop Unrolling,我编写了如下的代码:
1 |
|
可以想像,如果存在 Loop Unrolling,中间的加法运算就会被复制多次,而循环次数也对应减少。
使用 LLVM 进行编译,选择 O0 优化,即最低优化级别:
clang -O0 -S -emit-llvm unrolling.c
部分汇编代码如下:
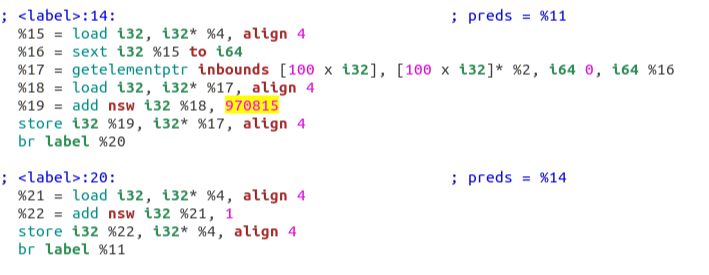
这里的代码不是真正的汇编代码,而是 LLVM 的中间语言(IR)。clang 作为 LLVM 的前端,负责解析 C 代码,之后 LLVM 会生成 IR 代码并作优化,最后由 IR 再翻译成平台相关的汇编代码。
这里 970815 (我的生日)是一个 magic number,通过这个数字我们可以迅速定位到循环的位置。可以看到,并没有什么稀奇之处,这个加法运算只出现了一次。
如果使用 O3,即最高级别优化:
clang -O0 -S -emit-llvm unrolling.c
可以看到 IR 代码如下:

这里可以很明显的看到,相加运算被复制了很多很多次,即编译器做了 Loop Unrolling 优化。当然,真实的代码可能会和 IR 有所出入,因为在 IR 中,寄存器的数量是无限制的,而真正的 CPU 的寄存器数量很少,所以会有所变动。不过可以确定的是,在 LLVM O3 级别的优化下,确实产生了 Loop Unrolling 现象。
使用 gperftools 测试性能
Linux 下有很多性能分析工具,这里我选择了可以配合 clang 使用的 Google gperftools。注意,gperftools 每隔 10ms 做一次采样,因此我设置的循环次数较大,这样才能有足够的时间来统计采样次数。而采样次数也就反映了程序的运行时间。
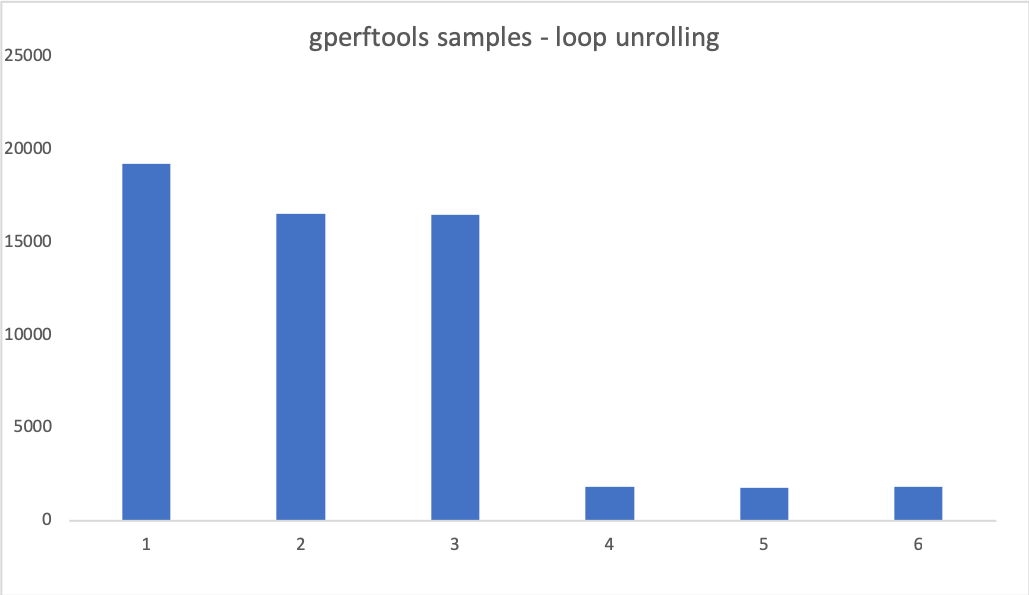
这张图中,纵坐标是 gperftools 的采样次数(与程序耗时成正比),前三组数据使用 O0 优化,而后三组数据使用 O3 优化。在 clang 中,即使是 O0 级别也是会做出一些基本的优化的。如果想要完全不优化,则需要自己更改 clang 的源代码。(逃
不过根据前面的 IR 代码可以知道,O0 是没有 Loop Unrolling 的。
通过这组数据可以看出,在有 Loop Unrolling 的情况下,性能的提升是显著的。虽然 O3 级别优化肯定也会对其他地方进行优化,但是在如此简单的情景下,可以假定对影响程序时间起主要作用的就是对循环作出的优化。
使用 gem5 模拟器分析
在刚才的分析中,我是使用了 VMWare 的 Linux 虚拟机来做的测试。然而,这样的测试变量较多,如系统的负载在不同时刻不一致等。使用 CPU 模拟器,可以得到非常精确的结果。
Gem5 有两种运行模式,SE 和 FS。SE 是 system emulation 的缩写,即模拟了 system call,而并没有真实的操作系统。这是一种较低层次的虚拟化技术。SE 模式下可以运行一些简单的静态编译程序(Linux 格式)。所以,在编译完成后,我将可执行文件从 Linux 虚拟机拷贝回宿主 macOS 上,并交给 gem5 执行。为了静态链接,需要在编译时添加 --static 参数。
clang -O3 unrolling.c -o unrolling_3 --static
未优化时,消耗的 CPU tick 数为:43233500。优化后为:40620500。可以看到优化后性能有所提高。提升没有之前显著的原因是,我将循环次数减少了数万至数十万倍。这是因为 gem5 效率更低,在之前的循环数量下会消耗过长的时间进行仿真。
使用 gem5 仿真的命令是:
build/X86/gem5.opt configs/turtorial/two-level.py
这里,使用 opt 模式 X86 架构的模拟器,而后一半是自行编写的 CPU 配置脚本。通过自定义配置脚本,可以指定 CPU 参数,cache 系统等。当然,gem5 本身也提供了一些现成的配置供我们使用。
运行完毕后,gem5 会在 m5out 文件夹下生成 stats.txt 文件展示统计信息。通过统计信息可以看到 cache 命中率等信息。
下面是优化后的缓存 miss rate:
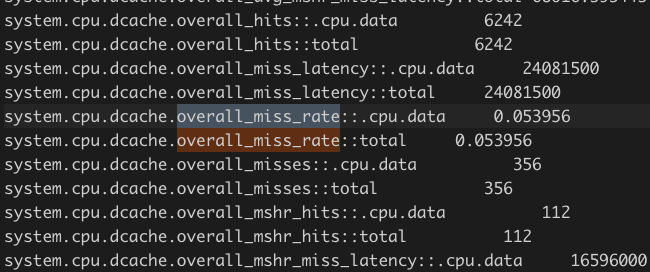
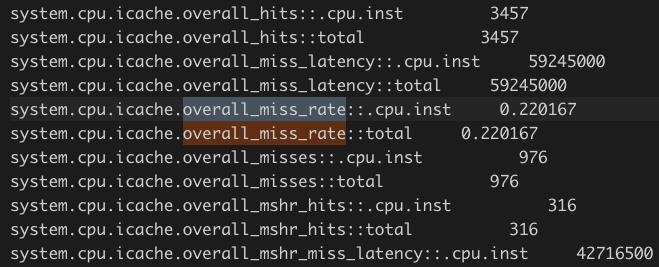
下面是未优化的:
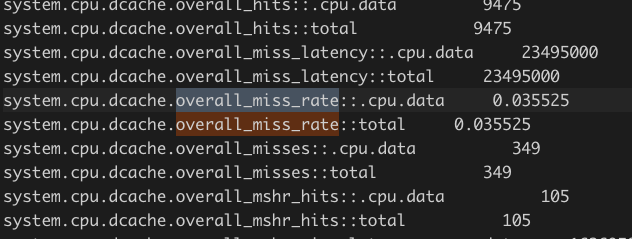
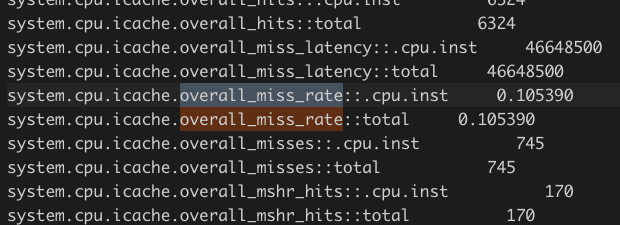
可以看到缓存 miss 比率在优化后反而升高了。这不能解释我们观察到的性能提升现象。(为什么 cache 反而命中率低了?我目前没有想到合理的解释)
使用现有的配置文件,gem5 可以可视化的展示 CPU pipeline。不过要知道,静态链接后程序会变得非常臃肿。而且,真实的汇编代码可读性很低,所以需要找到办法在完整的 pipeline 中找到我们感兴趣的循环部分。
为了定位循环的位置,首先阅读一下真实的汇编代码:
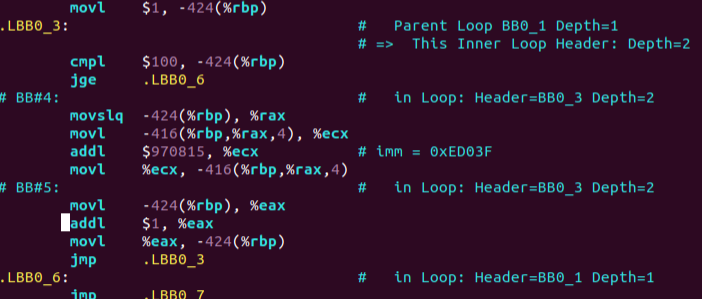
通过 magic number 970815 可以看到对应的 addl 指令位置。而这个立即数的 16 进制值为 imm = 0xED03F。
通过 objdump 工具可以反汇编出可执行文件的结构:
objdump -d unrolling_3 > obj.txt
输出的结果默认是打在控制台上的,但由于静态链接后程序体积非常大,我把输出结果重定向在 obj.txt 文件中,方便查看。
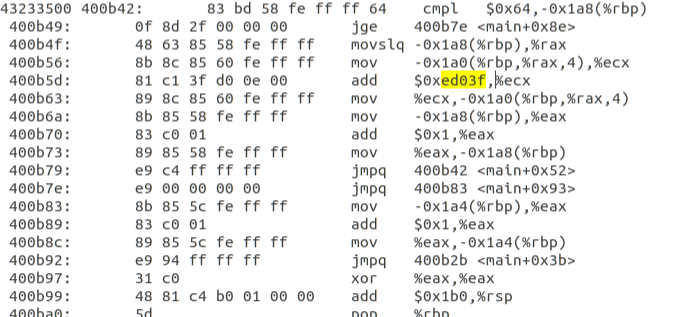
搜索 magic number 0xed03f 可以快速定位到位置。可以看到 address 是 0x400b5d 。由于这里是 SE 模式模拟,可以理解为程序在裸的 CPU 上运行,所以可以假象运行时的 PC 值就是这个地址。
使用 gem5 提供的 CPU 配置和可视化工具,可以检查 pipeline。
1 | build/X86/gem5.opt --debug-flags=O3PipeView --debug-start=1 --debug-file=trace.out configs/example/se.py --cpu-type=DerivO3CPU --caches -c /Users/wangluyuan/Desktop/COProject/test/unrolling_0 |
这里需要注意的是,官网教程中,向 se.py 传入的参数是 --cpu-type=detailed 。然而实际上 se.py 并不支持这个参数,可能是教程太过于陈旧了。需要传入的参数实际是 DerivO3CPU。
之后把输出结果格式进行转换:
./util/o3-pipeview.py -c 250 -o pipeview.out --color m5out/trace.out
最后打开:
less -r pipeview.out
这里的颜色是通过逃逸字符实现的,所以一般的文本编辑器打开是看不到颜色,而只能看到逃逸字符本身。所以最好使用 less 打开。
通过之前的 address 可以在完整的 pipeline 中找到加法对应的位置。当然,如果不想查看完整的 pipeline (太长了),可以在运行时指定参数 --debug-start:
1 | build/X86/gem5.opt --debug-flags=O3PipeView --debug-start=33800000 --debug-file=trace.out configs/example/se.py --cpu-type=DerivO3CPU --caches -c /Users/wangluyuan/Desktop/COProject/test/unrolling_3 |
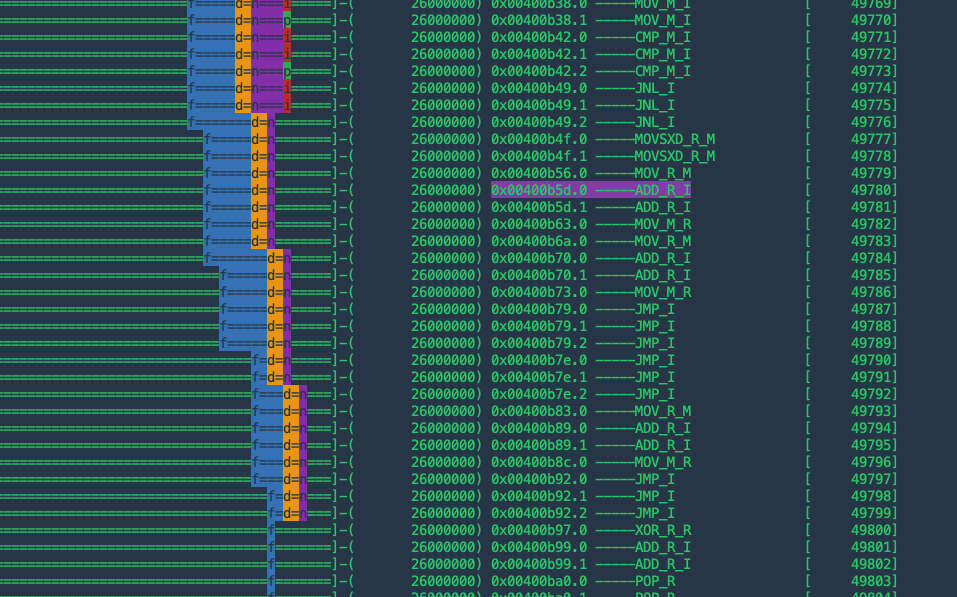
优化前:
优化后:
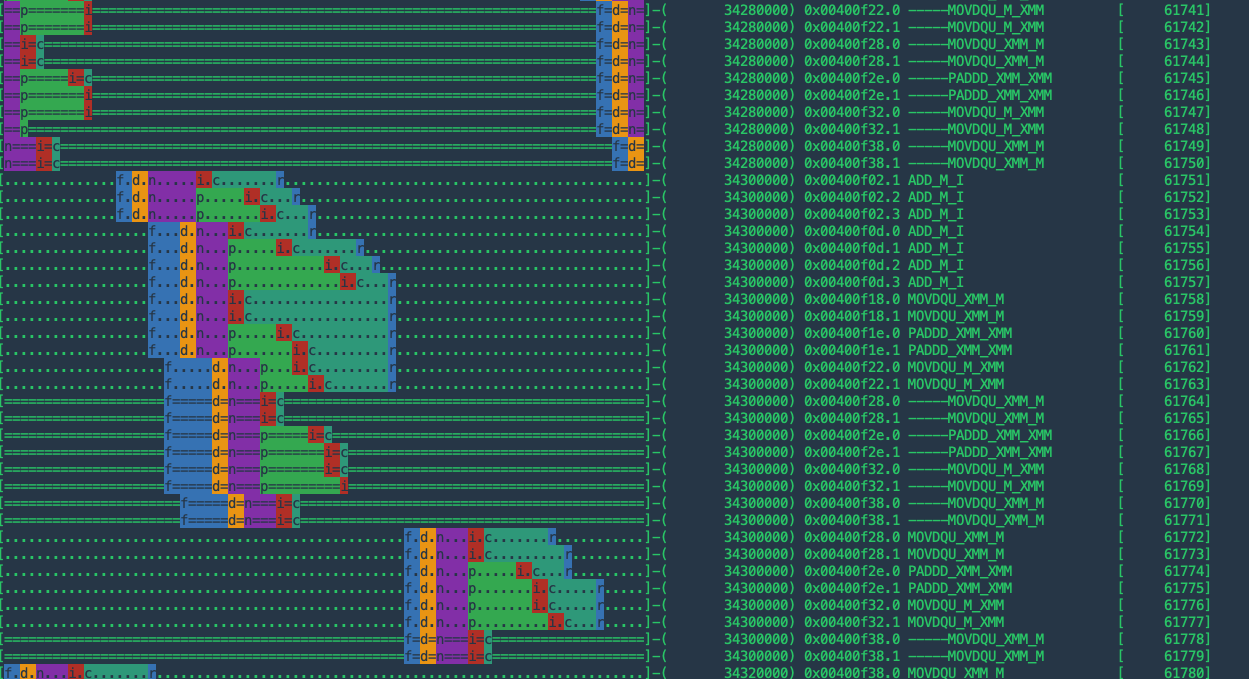
优化后,ADD 指令连续出现了多次。这里,不同的字母代表流水线的不同 stage:
1 | f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire, s = store-complete |
X86 的流水线比 MIPS 的五段(fetch, decode, exe, mem, wb)流水线复杂很多。但直观上来看,优化后的流水线似乎更满、更完整。或许是这个原因导致的运行速度更快。