Grad-CAM Overview
我们经常在论文中见到下面这种 CNN 的可视化图,它能告诉我们神经网络在做预测时,更加关注哪部分的内容,从一定程度上解释了判定依据。比如下图中,神经网络预测的分类是 ‘cat’,猫所在的区域温度就显著更高;而狗的位置就没有反应。

那么这种可视化是怎么产生的呢?一种方式是通过注意力机制,在训练时就让神经网络去学习像素的权重。这样权重高的位置就是更重要的部分,自然也就是网络更关注的地方。但这需要我们去给网络加入相应的注意力模块,需要对网络进行修改并重新训练。而通过 Grad-CAM,我们不需要对网络做更改,就可以得到这样的可视化数据。
CAM
在介绍 Grad-CAM 之前,必须先简单介绍一下 CAM,Class Activation Mapping。 这是 2016 年发表在 CVPR 的工作,具体工作原理如下:
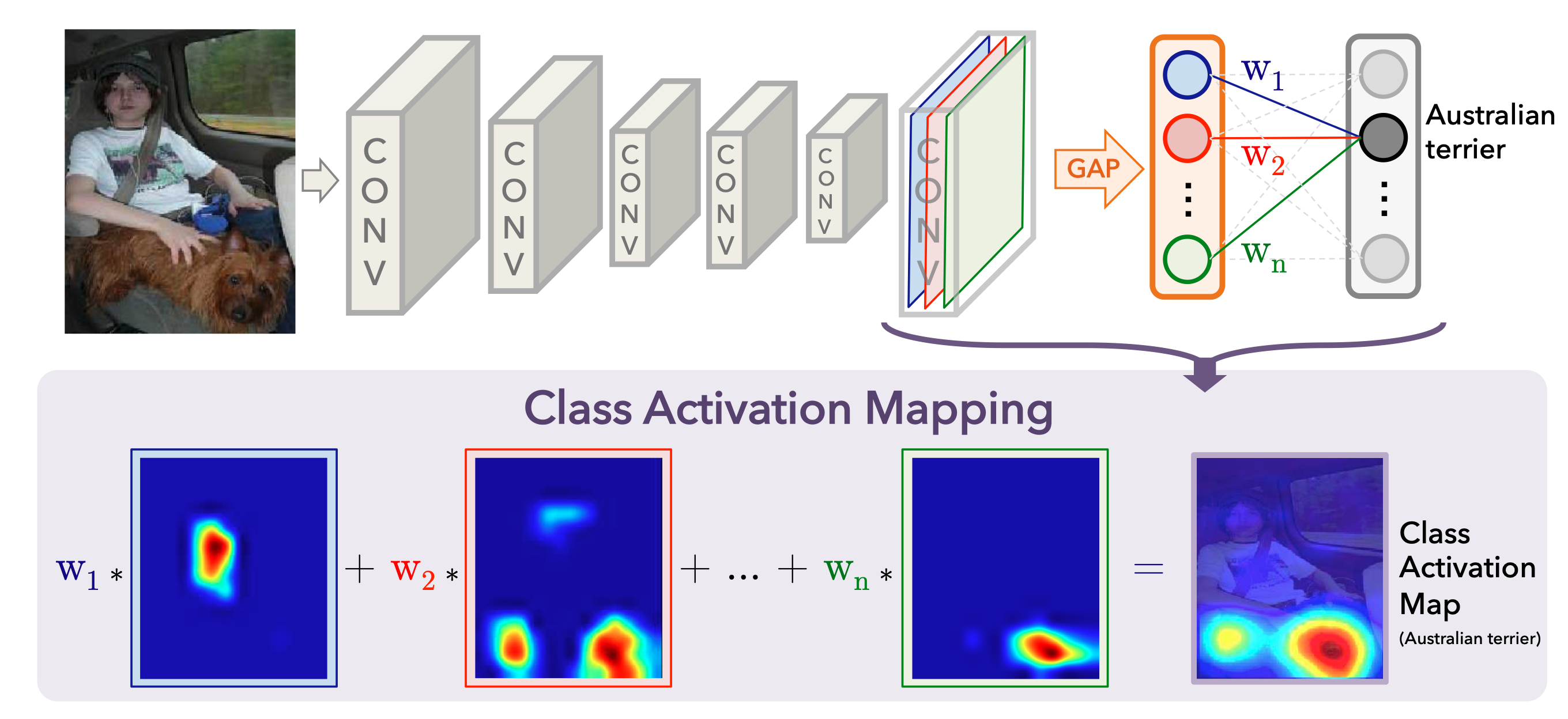
输入的图片比较复杂,可以想象输出层的神经元对人和狗应该都有比较强烈的反应。CNN 中,每过一次卷积都会产生新的 feature map。最后一层 feature map 尺寸比较小,但是提取出了最抽象的特征,并蕴含着全局的信息。卷积天然就含有图片空间域的信息,而再之后的全连接层就会把空间域的信息丢失了,因此我们对最后一次卷积出来的 feature map 最感兴趣。
设最后一层 feature map 包含 n 个通道。CAM 通过全局平均池化(GAP)将每个通道压缩为一个值,变成 1x1xC 维度的 tensor,之后再通过 FC Layer 来做分类。假如输出层中,第二个神经元代表狗,那么与之相连接的权重 w1, w2, … wn 就体现了不同特征的重要程度。如图做一次加权,就可以得到热图了。
Grad-CAM
CAM 的思路非常简洁,但是有一个缺点,就是必须依赖网络中存在 GAP 层。虽然许多现代的神经网络本身就含有 GAP 层,但是如果没有,就必须对网络进行修改再重新训练了。Grad-CAM 可以克服这一缺点,具体原理如下:
第一步,计算某个类相对 feature map 的导数:
$$
\frac{\partial y^{c\space=\space cat}}{\partial A^k}
$$
这里 y_c 代表针对某一类的输出,比如 ‘cat’。A_k 代表最后一层,第 k 个通道的 feature map。
第二步,做全局平均池化:
$$
\alpha_k^c = \frac{1}{Z}\sum_i\sum_j \frac{\partial y^c}{\partial A^k_{i, j}}
$$
这里得到的 alpha 值就相当于之前的权重,它反映了某个通道的重要程度,即某个特征对结果的贡献程度。
第三步,加权、ReLU:
$$
L^c_{Grad-CAM} = ReLU(\sum_k \alpha_k^c A^k)
$$
为什么需要 ReLU 呢?这里和激活函数没有关系,我们只是想把负数置为 0 而已。因为我们只关心对分类结果有正向影响的地方。负数的地方可能代表着图片中属于其他类别的地方。
最后计算出来的热图尺寸其实和最后一层的 feature map 是一致的,很小。但不要紧,直接插值缩放就好了。
PyTorch 实现
为了计算 heatmap,我们需要拿到最后一层卷积的 feature map,以及输出结果相对它的导数。最后一层的 feature map 很好得到,因为是正向传播,直接改 forward 代码就可以了。但是导数的反向传播是 PyTorch 自动计算的,我们该怎么拿到呢?其实 PyTorch 提供了 foward_hook 和 backward_hook ,利用 hook 函数就可以很方便的得到这两个值。
1 | class GradCAM(): |
完整的代码上传到了 GitHub Gist 上:https://gist.github.com/BeBeBerr/5af065430dece675f2b585f260108998
Experiments
使用上面的代码运行了两组实验:
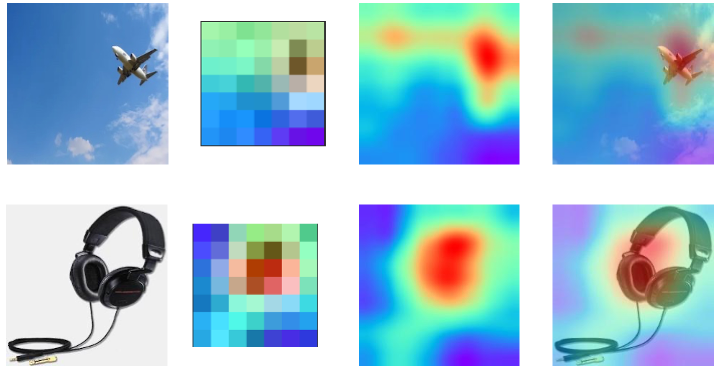
顺序分别为原图、heatmap 本身、resize 后的 heatmap、heatmap 和原图的叠加。可以看到 heatmap 本身的尺寸是非常小的,在 MobileNet 中,最后一层卷积的输出只有 7x7。但是通过插值缩放后仍能体现出位置关系。可以看到飞机和耳机的关键区域温度是最高的,其他地方相对温度较低。这个实验结果符合直觉。
References
[1] https://glassboxmedicine.com/2020/05/29/grad-cam-visual-explanations-from-deep-networks/